Web Scraping static web pages in .Net Core
by Christopher Long, on 18 May 2022Overview
I was talking to a developer friend the other day about starting a little side project where you could keep track of the product prices on supermarket websites and trend them over time. This would allow a user to see what’s increasing in price at any given moment. Unfortunately, none of the major supermarkets offer convenient API’s to easily get this information. Tesco’s used to offer a handy API, but it was decommissioned in 2016, sad face. This left me with a slightly less elegant method of getting the data I wanted, web scraping. This is something I have very little experience in, so it’s time to start at the basics.
What is Web Scraping?
Simply put, web scraping is your program using a regular old HTTP request to go off to a website of your choosing and grab all the HTML/CSS from the page. Usually, you’d then want to parse the results, only saving the data you’re interested in. You need to use different methods of scraping for different types of web pages. To start with we’re going to look at how to get data from static web pages.
Prerequisites
I’m going to be building this in a .Net Core Web Application using MVC. So, if you’re following along, go ahead and create a new project.
I’ll also be making use of the “HTML Agility Pack” which you can find via the NuGet package manager:
 This package makes parsing the HTML content much more intuitive.
This package makes parsing the HTML content much more intuitive.
Retrieving the HTML
Fortunately for us, .Net Core includes native asynchronous HTTP request libraries. Lets get us some HTML!
First step is choosing the web page we want to scrape, as I mentioned we’re starting with static pages, so I’ve chosen a Wikipedia page dear to all our hearts.

As you can see above I’ve placed the URL variable in the HomeController Index() method as this is the default call when you first open an MVC web application.
When using the .NET HTTP library, a static asynchronous task is returned from the request, so we’ll need to build out the code to handle the request functionality in its own static method.
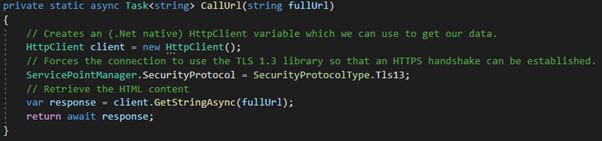
I’ve added this to the HomeController class to keep things simple. I’ve also updated the Index() method to call the method on our URL.

Let’s quickly test that we’ve set things up correctly and are receiving the HTML data. The easiest way to do this is to place a breakpoint on the return View(); line and run the program.
 Looks good! Now to parse the data.
Looks good! Now to parse the data.
Parsing the HTML
The first step in parsing the HTML is knowing what we’re looking for. For this exercise I’m happy with just getting all the individual programming languages held on the page.
Inspecting the programming names in the chrome dev tools shows us that each name is contained in an <Li> element.
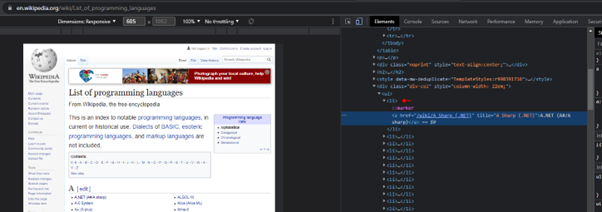
Let’s grab all the <Li> elements on the page and see what we get.
First I’m going to create a new method to parse the HTML.
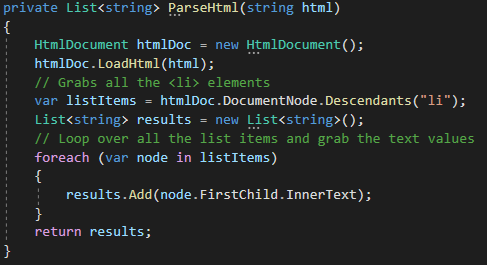
While writing the method I used breakpoints to see the structure of the list items, the InnerText property appears to contain the data I want.
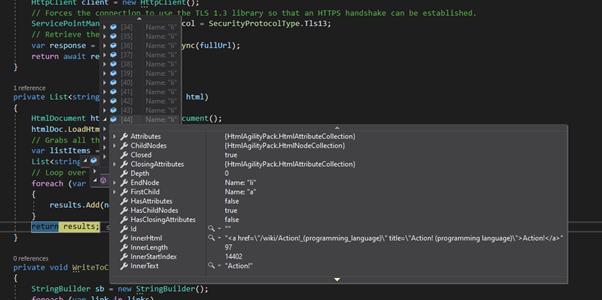
The problem with this approach is that there are a lot of other <Li> elements on the page and I’m getting their values as well, like this.
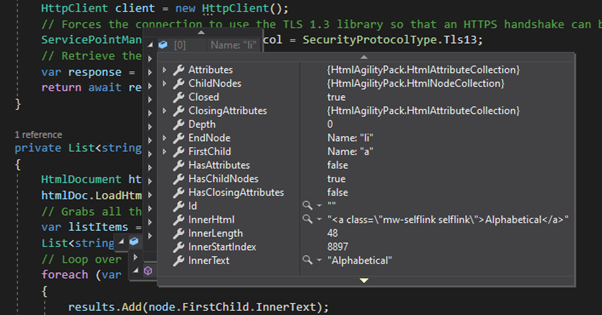
By poking around in the HTML source I was able to get values from the elements, or their parent nodes that I could start using to filter out some of the unwanted data.
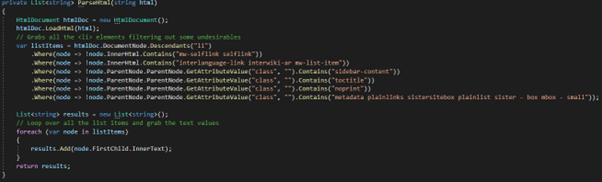
I didn’t sanitize the whole list since I don’t really have any plans for the data here, but you can see the method I used and see how that could be incorporated in your own code.
Saving the filtered data
It may be more convenient in your project to just save the data and do the sanitizing some other way after the fact. Since we’re keeping things simple lets just write a quick method to export this data to a .txt file.
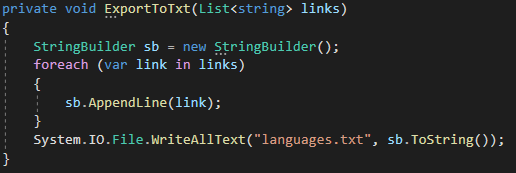
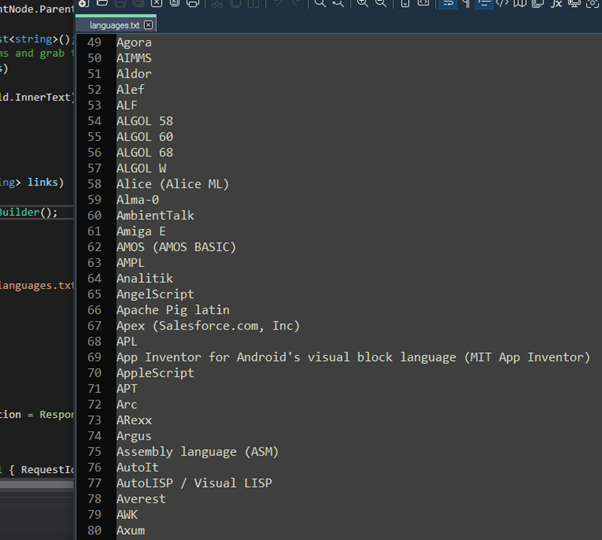
And boom, here’s out output:
Conclusion
Web scraping is one of the various methods available to a developer who needs to make use of a web page’s content. In this article I covered a basic but powerful implementation, I hope to also cover scraping dynamically created webpages in the future.
Cheers!